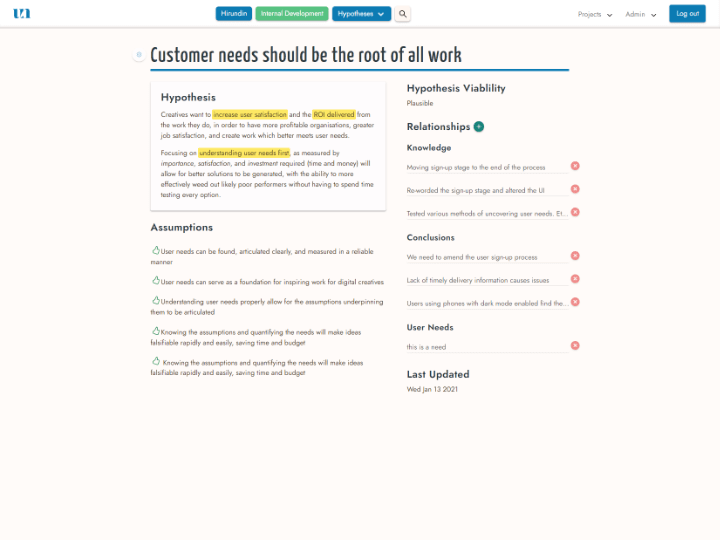
Customer-Led Product Management.
Hirundin puts customer needs at the center of product management, helping product teams think, experiment and prioritize strategically.
Deliver work users want
better & faster
We built Hirundin to help product, design and UX teams. It's designed to help you understand customers and users, and make decisions based on their needs and goals. We've designed a suite of tools which radically improve how you think about what you build, ensuring you only create work with provable value, log your strategy, and show value to stakeholders all the way through your process.
We call it scientific product management.
We've found that this idea of thinking of our work as if it were a series of experiments really frees up our thinking. It allows us to try more innovative ideas, crazy ideas and maybe even stupid ideas, but in a small-scale, contained way first, to really understand what the effects are of what we're doing.
Navin Iyengar
Netflix
Put hypotheses together, go and look at the data and think "well this could mean a couple of different things, let's go actually talk to real people and validate it". Don't go data-blind and take the numbers at face value, because that can be misleading. This hybrid approach can radically change your experience.
Stephen Gates
InVision
User Needs, Journeys & Insights, with Prioritization & Roadmaps
Create customer journey maps built around qualitative as well as quantitative data, which live and develop as your organization and understanding evolves. Construct goal-directed archetypes designed to help you better reflect on user goals requirements. Use purpose-designed scientific strategic research and prioritization, built to help product teams think critically and remove time which would otherwise be spent creating things which would fail, and to show process and the thinking behind decisions. Build now, next, future outcome roadmaps, which accurately reflect your strategic priorities and the outcomes you want to see to help users.
Scientific Product Management
 Listen & Observe
Listen & Observe
See how your users behave, listen to their opinions, and find common traits, desired outcomes and unmet needs in what they do.
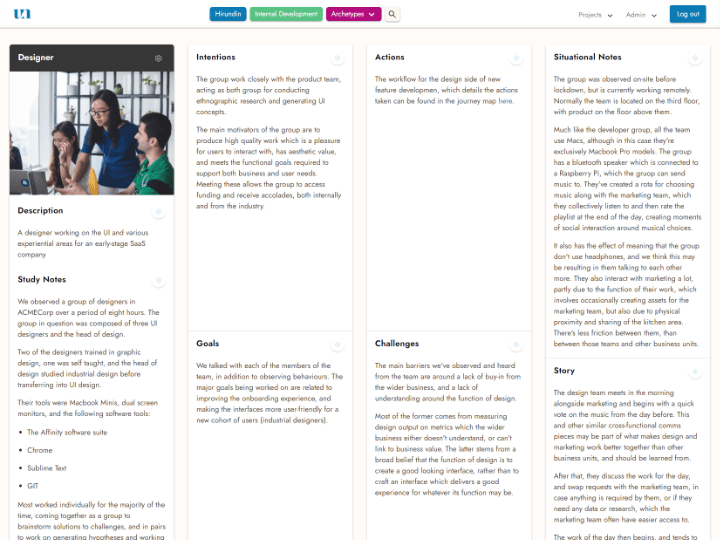
 Research & Ideate
Research & Ideate
Create hypotheses and think critically about how to address the uncovered needs and challenges to deliver better experiences.
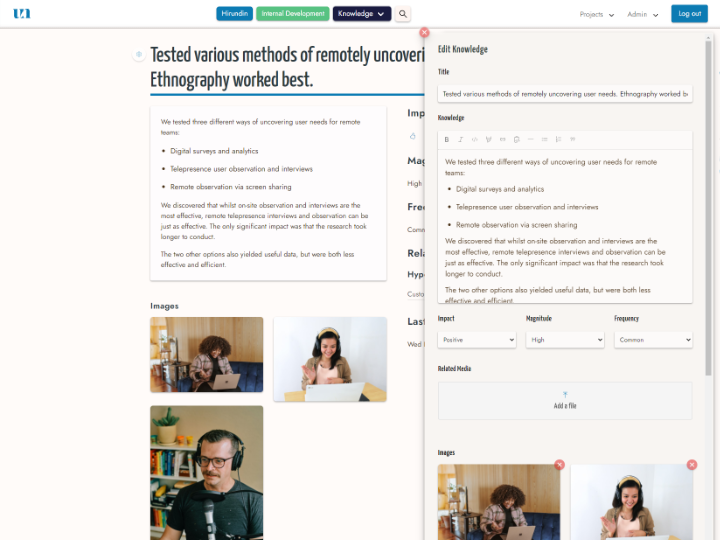
 Experiment & Learn
Experiment & Learn
Test your ideas to see which are robust and should be built, and which don't hold up under scrutiny.
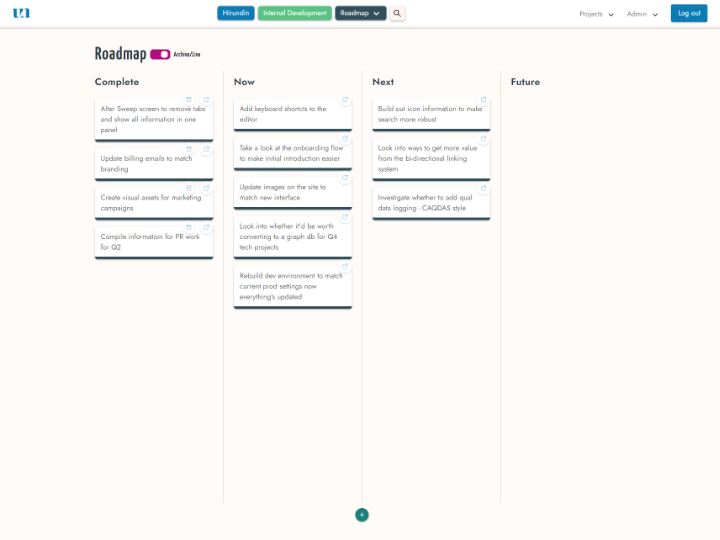
 Roadmap & Build
Roadmap & Build
Implement evidenced-based changes which deliver measurable improvements for people using your services.
Coming soon...
Hirundin
Go to feature: